之前的文章中,给大家介绍了如何将OpenCV 2.2与CUDA 4.0的巧妙结合。今天尝试把CUDA 和 OpenCV 两者进行硬性结合。
建立一个 project,添加一个.cu 的文件。
按照之前的方法进行 OpenCV 和 CUDA 的配置:
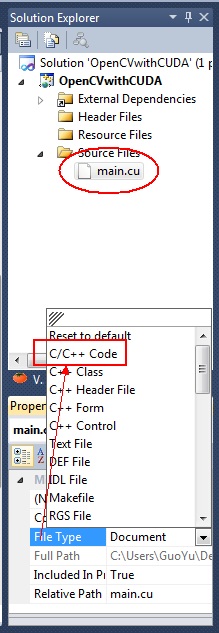
我们看到.cu 文件的图标不好看,可以在属性中 File Type 项选择 C/C++ Code。
这样 .cu 就变成了我们熟悉的图标,当然这些都是无所谓的事情。
添加代码,我把之前用来测试 OpenCV 和 CUDA 的代码放到了一起:
#include <iostream>
#include <highgui.h>
using namespace ::std;
///////////////////////////////////////////////////////////////////////////
#include <cv.h>
#include <highgui.h>
#pragma comment(lib, "ml.lib")
#pragma comment(lib, "cv.lib")
#pragma comment(lib, "cvaux.lib")
#pragma comment(lib, "cvcam.lib")
#pragma comment(lib, "cxcore.lib")
#pragma comment(lib, "cxts.lib")
#pragma comment(lib, "highgui.lib")
#pragma comment(lib, "cvhaartraining.lib")
///////////////////////////////////////////////////////////////////////////
__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width)
{
int tx = threadIdx.x;
int ty = threadIdx.y;
float Pvalue = 0.0;
for(int k = 0; k < Width; k++)
{
float Melement = Md[ty *Width + k];
float Nelement = Nd[k *Width + tx];
Pvalue += Melement * Nelement;
}
Pd[ty *Width + tx] = Pvalue;
}
void MatrixMulOnDevice(float* M, float* N, float* P, int Width)
{
int size = Width * Width * sizeof(float);
float* Md;
float* Nd;
float* Pd;
cudaMalloc(&Md, size);
cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);
cudaMalloc(&Nd, size);
cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice);
cudaMalloc(&Pd, size);
dim3 dimBlock(Width, Width);
dim3 dimGrid(1,1);
MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width);
cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost);
cudaFree(Md);
cudaFree(Nd);
cudaFree(Pd);
}
int main()
{
IplImage *img = cvLoadImage("E:\lena.jpg");
cvShowImage("Image:",img);
float M[3][3] = {
{1.0, 2.0, 3.0},
{4.0, 5.0, 6.0},
{7.0, 8.0, 9.0}
};
float N[3][3] = {
{1.0, 2.0, 3.0},
{4.0, 5.0, 6.0},
{7.0, 8.0, 9.0}
};
float P[3][3] = {0.0};
float* m = &M[0][0];
float* n = &N[0][0];
float* p = &P[0][0];
int Width = 3;
MatrixMulOnDevice(m, n, p, Width);
for (int i = 0;i < Width;i++)
{
for (int j = 0;j < Width;j++)
{
cout<<P[i][j]<<" ";
}
cout<<endl;
}
cvWaitKey();
return 0;
}
直接用 Debug 运行出错加一堆 warning,难道这样硬生生搬到一起就不行吗?
后来,同学用 OpenCV 1.0 和 CUDA 4.0 的组合顺利通过。
或者参考http://www.ademiller.com/blogs/tech/2011/03/using-cuda-and-thrust-with-visual-studio-2010/
再后来,用 Release 运行竟然通过了,而且结果正确,神了个奇,但是 warning 依然很多,看来不是个好方法。
但起码出结果了,我很不理解,看来我对 Debug 和 Release 的机制还不了解,以后再说。
顺便一提,这时图片路径使用绝对路径竟然就可以了。
http://cuda.it168.com/a2011/0920/1248/000001248712.shtml
分享到:




相关推荐
自己整理的opencv源码分析,是关于opencv2.2的,里面也有自己的翻译,如果大家喜欢,我陆续会把源码分析一个个上传完毕
Opencv 2.2 编译版本 Opencv 2.2 编译版本 vs2008
Opencv 2.2 编译版本 Opencv 2.2 编译版本
OpenCV2.2于vs2010的安装详细过程
Opencv2.2 在 VC2010 上的安装说明
vs2010与opencv2.2 一次性配置
此文档详细介绍了在vs2010下怎么安装opencv2.2,我的电脑也是这样安装的,成功了,希望对你有用。注意:我用的是xp系统+vs2010旗舰版+opencv2.2编译版
这是x64版本的opencv2.2,支持64位代码。
VS2008下opencv2.2的安装过程,有志搞图像处理的都看看。
opencv2.2在vs2010的基本安装方法,希望对您有用!
老版本opencv,opencv2.2,包含OpenCV-2.2.0-win.zip,OpenCV-2.2.0-win32-vs2008.exe,OpenCV-2.2-win-Readme.txt
介绍opencv2.2的新特性,新方法,还有opencv2.2的安装和配置方法
opencv_python-4.0.0.21-cp36-cp36m-win_amd64.whl文件,用来解决64位系统import cv2出错,在线cmd命令pip3 install opencv-python网速过慢也导致出错的问题。 操作方法:将文件下载后拷贝至Anaconda或者python安装...
opencv2.2帮助文档
OpenCV 2.2 Reference Manual 最权威的OpenCV编程参考
opencv 2.2的文件,大家有需要就下,这个可以和cmkae一起编译的,不过你要先安装cmake的
vs2015编译好的Opencv4.0+Contrib4.0+Releasex64版本。为什么改不了资源分数,默认为5,知道如何改的告诉我一下。我重新上传。
本资源是opencv的源码,主要是防止国外网址比较慢而提供国内的下载,如果需要具体某个编译器版本的库,请自己通过cmake进行编译。 另外一个方面,可能做科研的时候需要指定版本的库,可以通过源码生成库。
详细介绍轻量级编辑器如何配置opencv2.2
Window XP + VS2010 + OpenCv2.2 安装成功。前几天亲试。